


Tháng 5 này đánh dấu 5 năm Dolt sử dụng go-mysql-server. Nhân dịp này, chúng tôi chia sẻ lại toàn bộ hành trình mà một truy vấn SQL đi qua trong hệ thống từ lúc được phân tích cú pháp (parse) cho đến khi trả kết quả về.
1. Tổng quan
Trong một hệ quản trị cơ sở dữ liệu, SQL engine chính là tầng logic nằm giữa client (người dùng) và storage (lưu trữ). Khi người dùng muốn truy cập hoặc thay đổi dữ liệu, SQL engine sẽ xử lý theo trình tự:
-
Parsing (Phân tích cú pháp)
-
Binding (Gắn kết)
-
Plan Simplification (Đơn giản hóa kế hoạch)
-
Join Exploration (Tìm phương án JOIN)
-
Plan Costing (Ước lượng chi phí)
-
Execution (Thực thi)
-
Spooling Results (Trả kết quả)
Tùy từng hệ thống, có thể còn thêm nhiều chiến lược xử lý khác nhau (xử lý từng dòng hay theo vector, chạy cục bộ hay phân tán). Dolt hiện tại dùng xử lý từng dòng trong môi trường local.
2. Parsing – Phân tích cú pháp
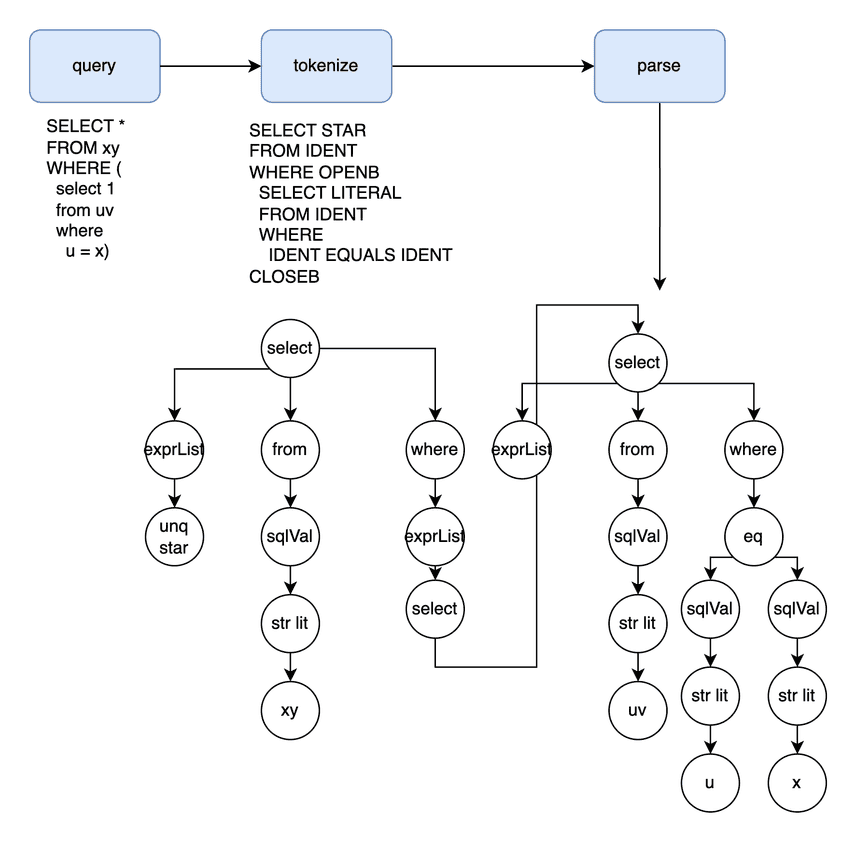
Đầu tiên, khi nhận được câu SQL, engine sẽ phân tích cú pháp để tạo ra cây cú pháp trừu tượng (AST). Đây là bước kiểm tra xem câu lệnh có hợp lệ về cấu trúc không.
Câu truy vấn từ client sẽ được gửi qua mạng tới server, nơi nó được xử lý bởi một handler (ComHandler). Câu truy vấn sẽ được chia thành từng token nhỏ rồi đưa vào quá trình phân tích.
Có 2 loại parser phổ biến:
-
Right-recursive parser: đơn giản, dễ debug, dùng khi parser đi từ trên xuống dưới. Nhưng dùng nhiều bộ nhớ stack.
-
Left-recursive parser: hiệu quả hơn, ít tốn bộ nhớ, xử lý từ dưới lên nhưng khó debug hơn.
Dolt sử dụng left-recursive parser thông qua Yacc, cho phép gộp các thành phần thành những biểu thức logic lớn, ví dụ như JOIN.
Các đoạn mã ví dụ được đưa ra để minh họa cách parser hoạt động khi gặp các trường hợp như table, join condition...
Nếu parsing thành công, AST sẽ tuân thủ đúng định nghĩa grammar. Nếu thất bại, client sẽ nhận được thông báo lỗi.
table_reference:
table_factor
| join_table
table_factor:
aliased_table_name
{
$$ = $1.(*AliasedTableExpr)
}
| openb table_references closeb
{
$$ = &ParenTableExpr{Exprs: $2.(TableExprs)}
}
| table_function
| json_table
join_table:
table_reference inner_join table_factor join_condition_opt
{
$$ = &JoinTableExpr{LeftExpr: $1.(TableExpr), Join: $2.(string), RightExpr: $3.(TableExpr), Condition: $4.(JoinCondition)}
}
join_condition_opt:
%prec JOIN
{ $$ = JoinCondition{} }
| join_condition
{ $$ = $1.(JoinCondition) }
join_condition:
ON expression
{ $$ = JoinCondition{On: tryCastExpr($2)} }
| USING '(' column_list ')'
{ $$ = JoinCondition{Using: $3.(Columns)} }3. Binding – Gắn kết với các đối tượng trong database
Sau khi parsing xong, hệ thống cần hiểu từng phần của câu lệnh đó ứng với bảng/cột nào trong cơ sở dữ liệu thực tế. Đây gọi là binding.
Binding giống như việc gán các biến trong lập trình: mỗi bảng, alias hay cột sẽ trở thành một biến có thể tham chiếu tới. Một số điểm chính:
-
Bảng (table definitions) là nguồn cung cấp dữ liệu (nhiều dòng, nhiều cột). Trong cùng một phạm vi, không được đặt tên bảng trùng nhau. Ví dụ:
select * from mydb.mytable.xy join xy on xlà lỗi vì có 2 bảng tênxy. Tuy nhiên, ngoài phạm vi hiện tại thì tên bảng có thể truy cập toàn cục. -
Subquery là một dạng biểu thức đặc biệt, thêm một lớp phạm vi tên riêng, nhưng vẫn hoạt động giống như một bảng. Ví dụ:
select sq.a from (select x as a from xy) sq -
Cột (column definitions) là nơi tiếp nhận dữ liệu từ bảng. Nếu trong cùng phạm vi có 2 cột trùng tên thì phải chỉ rõ bảng. Ví dụ:
select * from xy a join xy b where x = 2sẽ lỗi vì không biếtxthuộc bảngahayb. -
Alias (bí danh) là tên tạm, cho phép đặt tên mới cho bảng, cột hoặc biểu thức. Tuy nhiên, nếu dùng alias trước khi nó được định nghĩa thì sẽ bị lỗi. Ví dụ:
select x+y as a from xy where a > 2sẽ lỗi, vì aliasachưa tồn tại tại thời điểmWHEREđược xử lý. Ngược lại,having a > 2thì hợp lệ, vìHAVINGnằm sauSELECTtrong luồng xử lý. -
Scalar subqueries hoạt động giống alias nhưng phức tạp hơn, vì các phạm vi subquery vẫn kế thừa từ phạm vi cha. Ví dụ:
select (select a.x from xy b) from xy avẫn hợp lệ vìa.xđược tìm thấy trong phạm vi cha. -
CTE (Common Table Expressions) và alias subquery cũng áp dụng các quy tắc về phạm vi tên tương tự.
-
Ràng buộc tên (scoping): nếu trong các phạm vi khác nhau có trùng tên thì không sao, miễn là trong cùng phạm vi không trùng. Ví dụ:
select (select a.x from xy b) from xy avẫn hợp lệ vì biếnakhông tồn tại trong phạm vi củab, nhưng lại tồn tại ở phạm vi cha.
Binding sẽ chuyển AST thành các sql.Node đặc trưng của go-mysql-server.
4. Plan Simplification – Đơn giản hóa kế hoạch truy vấn
SQL rất linh hoạt về cách viết, nhưng hệ thống cần chuẩn hóa về một dạng dễ xử lý nhất. Mục tiêu là:
-
Gom các dạng tương đương về cùng một kế hoạch.
-
Tối ưu hóa hiệu năng.
Một số kỹ thuật phổ biến:
-
Filter pushing: đẩy điều kiện lọc sớm nhất có thể.
-
Column pruning: bỏ đi các cột không dùng đến.
Các bước này giống như tối ưu trình biên dịch.
Một ví dụ đặc biệt là decorrelate subquery: biến câu có truy vấn con thành dạng JOIN để xử lý hiệu quả hơn.
5. Type Coercion – Chuyển đổi kiểu dữ liệu
Cùng một biểu thức nhưng tùy ngữ cảnh mà kiểu dữ liệu có thể khác:
-
Trong INSERT: ép về kiểu của cột.
-
Trong WHERE: ép về boolean.
Dolt đang dần chuyển việc kiểm tra kiểu từ giai đoạn execution sang binding.
6. Join Exploration – Tìm phương án JOIN
Khi truy vấn có nhiều bảng cần JOIN với nhau, có rất nhiều cách để sắp xếp thứ tự thực hiện JOIN. Mỗi cách sẽ ảnh hưởng đến tốc độ thực thi truy vấn. Vì vậy, SQL engine sẽ phải khám phá các phương án JOIN khác nhau và ước lượng chi phí để chọn ra phương án tối ưu nhất.
Việc khám phá này gồm 2 phần:
-
Search (Tìm kiếm): liệt kê tất cả các cách kết hợp bảng có thể xảy ra và vẫn đảm bảo tính đúng.
-
Costing (Ước lượng chi phí): với mỗi cách, tính toán chi phí thực hiện để so sánh.
6.1 Join Search – Khám phá thứ tự JOIN
Có hai chiến lược phổ biến:
-
Backtracking từ trên xuống (Top-down): hệ thống sẽ thử lần lượt các tổ hợp bảng có thể JOIN, tránh lặp lại những tổ hợp đã thử. Nếu gặp tổ hợp không hợp lệ thì bỏ qua. Cách này nhanh hơn nhưng có thể bỏ sót những cách tốt nhất.
-
Quy hoạch động từ dưới lên (Bottom-up Dynamic Programming): thử tất cả mọi tổ hợp từ 2 bảng, 3 bảng... đến n bảng. Cách này đảm bảo tìm ra cách tốt nhất nhưng tốn thời gian hơn.
Dolt sử dụng chiến lược thứ hai, kết hợp với một bộ phát hiện xung đột thông minh gọi là DP-Sube, cho phép khám phá nhiều khả năng hơn mà vẫn đảm bảo tính đúng.
Mỗi cách JOIN không chỉ khác về thứ tự bảng mà còn khác về kiểu JOIN:
-
LOOKUP_JOIN
-
HASH_JOIN
-
MERGE_JOIN
Ví dụ: JOIN 3 bảng ab, uv, xy có thể tạo ra các tổ hợp như:
-
(ab JOIN uv) JOIN xy
-
ab JOIN (uv JOIN xy)
Các tổ hợp này sẽ được gom vào các nhóm gọi là memo groups. Mỗi nhóm lưu lại các cách JOIN cho cùng một kết quả logic. Khi tìm ra phương án JOIN tốt nhất trong nhóm, hệ thống có thể tái sử dụng cho các truy vấn khác.
6.2 Functional Dependencies – Quan hệ khóa chính/phụ
Khi JOIN quá nhiều bảng (5+), việc thử hết mọi tổ hợp sẽ tốn thời gian. May mắn là trong thực tế, các bảng thường có mối quan hệ khóa chính - khóa ngoại (primary key - foreign key) rõ ràng.
Ví dụ: bảng orders JOIN với users qua user_id. Khi đó, JOIN nên thực hiện theo hướng từ bảng nhỏ sang bảng lớn và sử dụng LOOKUP_JOIN để tối ưu.
Dolt có tích hợp phân tích quan hệ khóa để giúp việc JOIN hiệu quả hơn.
7. Join Costing – Ước lượng chi phí JOIN
Sau khi đã liệt kê tất cả các phương án JOIN có thể, hệ thống sẽ ước lượng chi phí để chọn ra phương án tối ưu.
Các yếu tố ảnh hưởng đến chi phí:
-
Số lượng dòng đầu vào (Input Size)
-
Số lượng dòng sau JOIN (Output Size)
-
Loại JOIN sử dụng (LOOKUP, HASH, MERGE...)
Ví dụ, JOIN hai bảng mà mỗi bảng có hàng triệu dòng sẽ tốn chi phí cao hơn JOIN hai bảng chỉ có vài chục dòng.
Để ước lượng chi phí, hệ thống sử dụng histogram (biểu đồ phân phối giá trị) để mô phỏng số lượng dòng sẽ trả ra sau JOIN.
Ví dụ truy vấn:
select * from xy where exists (select 1 from uv where u = x);
Hệ thống sẽ liệt kê các phương án JOIN và tính toán chi phí từng cách, như:
-
lookupjoin giữa xy và uv
-
semijoin
-
hashjoin
Mỗi phương án được gán một con số đại diện cho chi phí (ví dụ 6.6, 4.0...). Từ đó chọn ra cách JOIN ít tốn tài nguyên nhất.
Dolt sử dụng thống kê deterministic – nghĩa là kết quả thống kê không thay đổi theo thời gian, giúp việc ước lượng ổn định và đáng tin cậy hơn.
nguồn: https://www.dolthub.com/blog/2025-04-25-sql-engine-anatomy